Run LLMs Locally using Ollama
"A guide to the Ollama framework to try out LLMs locally"
By Naveen Karthik
01/01/2025
Running large language models (LLMs) like ChatGPT and Claude usually involves sending data to servers managed by OpenAI and other AI model providers. While these services are secure, some businesses prefer to keep their data entirely offline for greater privacy.
Using LLMs on local systems is becoming increasingly popular thanks to their improved privacy, control, and reliability. Sometimes, these models can be even more accurate and faster than ChatGPT.
Why Run LLMs Locally?
Running LLMs locally involves deploying advanced AI models directly on personal or organizational hardware, rather than relying on cloud-based services. This approach offers several advantages:
- Data Privacy: Processing data in-house ensures sensitive information remains confidential
- Reduced Latency: Local execution eliminates network communication delays
- Customization and Control: Enables fine-tuning without third-party constraints
- Cost Efficiency: Bypasses subscription fees and usage costs
Introduction to Ollama
Ollama is an open-source tool that runs large language models directly on a local machine. It's particularly appealing to AI developers, researchers, and businesses concerned with data control and privacy.
By running models locally, you maintain full data ownership and avoid cloud storage security risks. Offline AI tools like Ollama also help reduce latency and reliance on external servers.
Setup Guide
1. Installation
First, download and install Ollama from ollama.com/download
2. Initialize Server
After installation, initiate the Ollama server and CLI in your local system:
3. Access Ollama
Open Command Prompt to access Ollama:
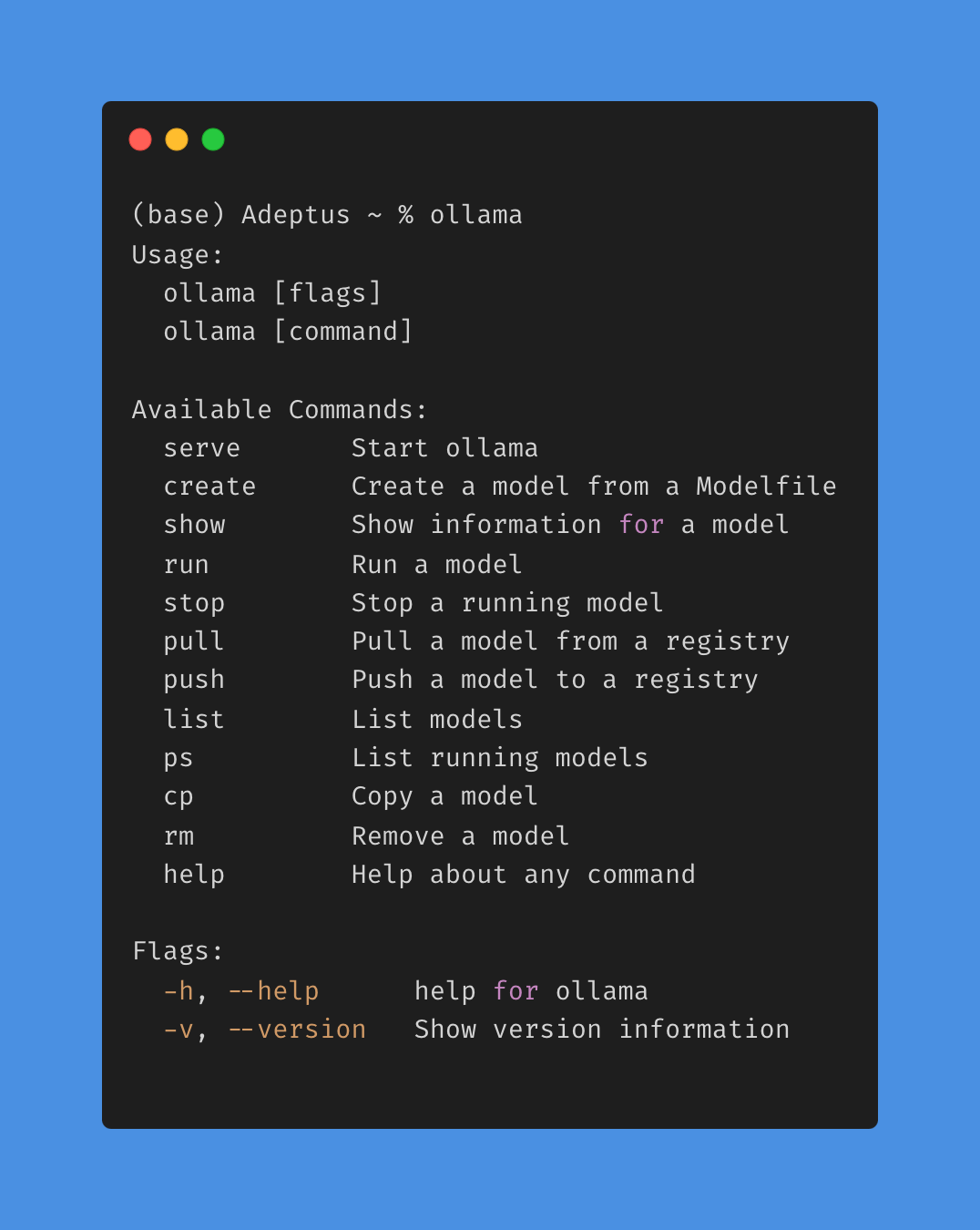
4. Model Selection
Browse the Ollama Model Library and pull your chosen model:
ollama pull <Model_name>
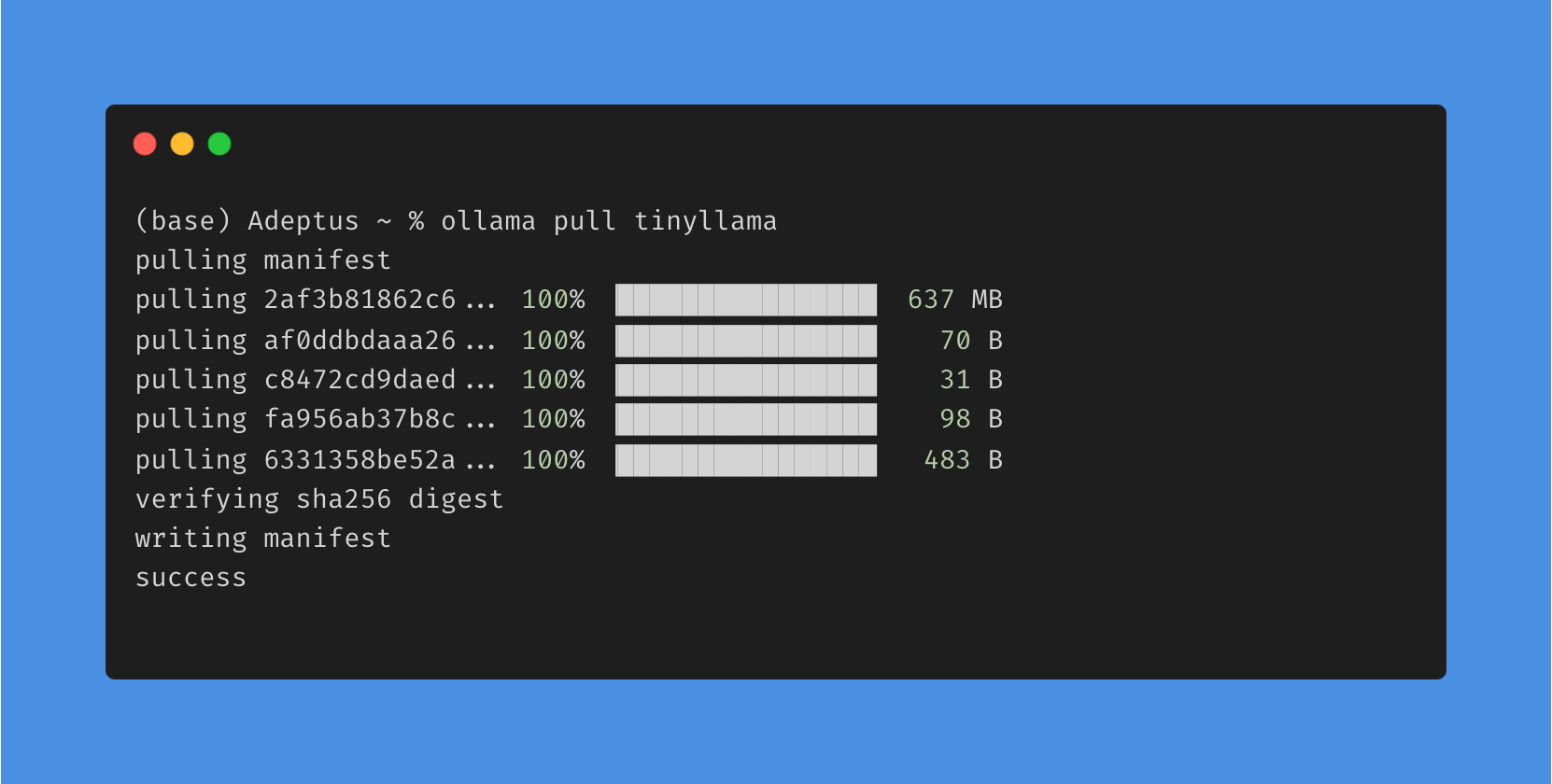
5. Running Models
Use the run command to interact with your model:
ollama run <Model_name>
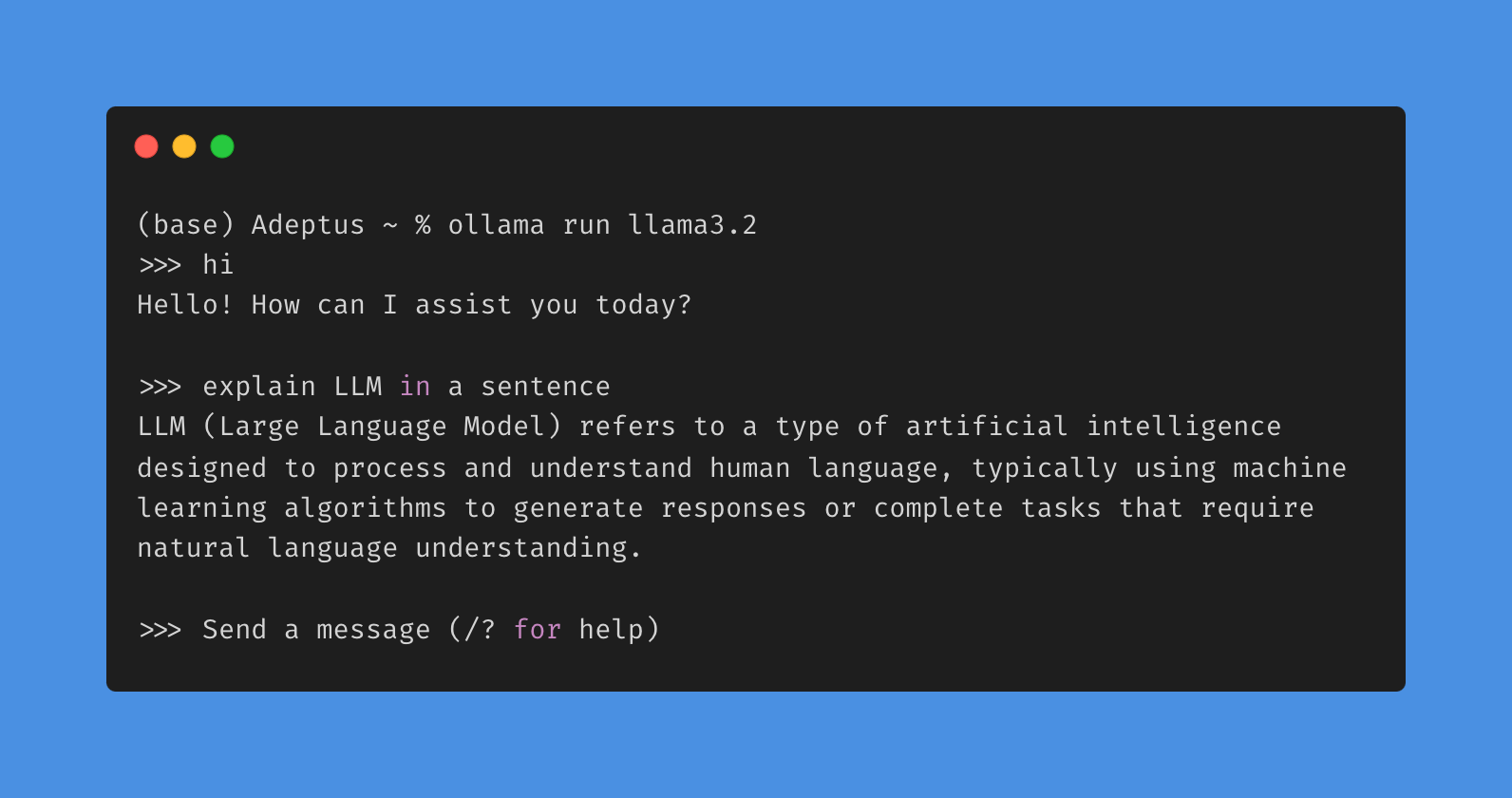
6. Code Integration
You can integrate these LLMs into your codebase using libraries like langchain or llama_index:
# Example Integration

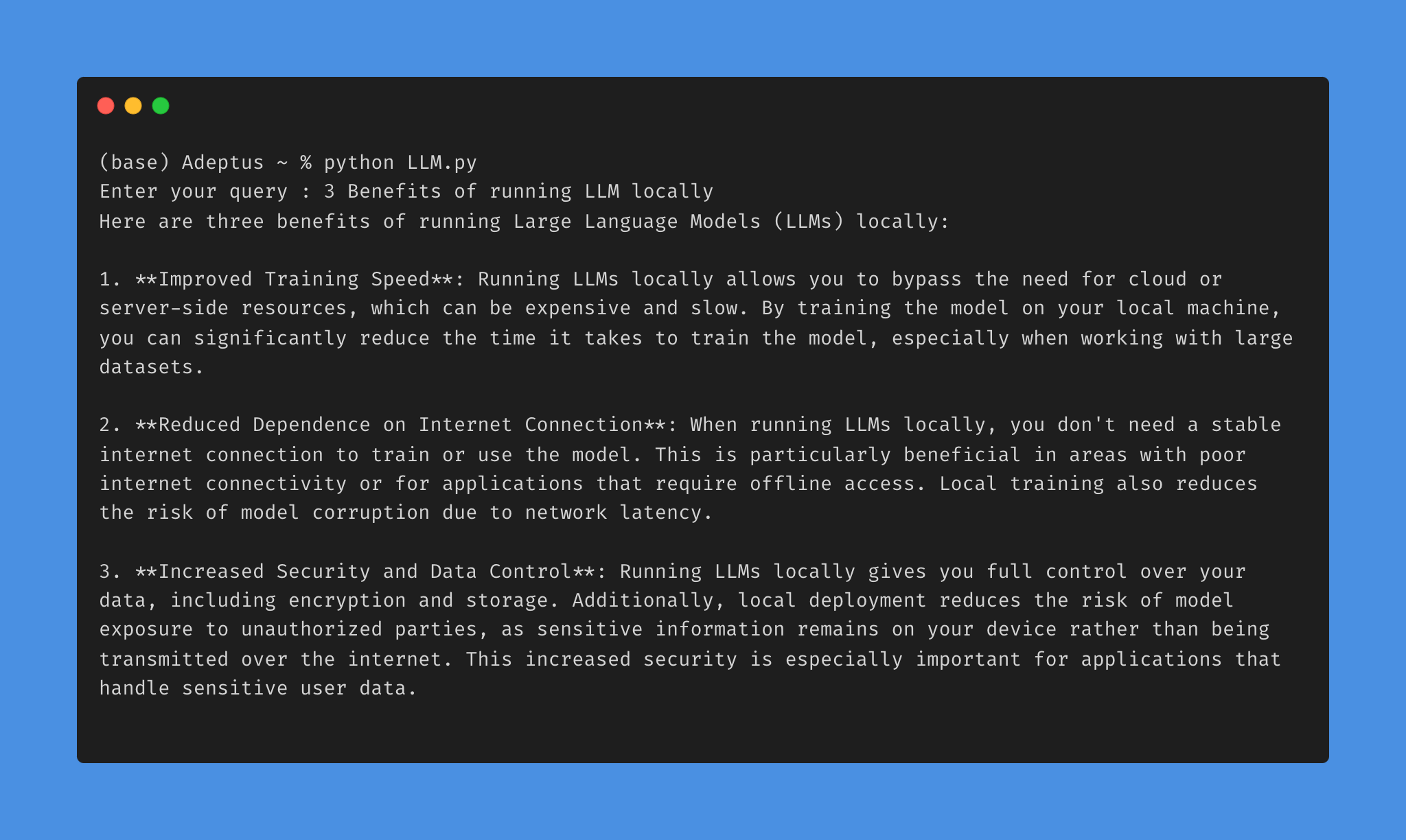
7. Model Management
List installed models using:
ollama list
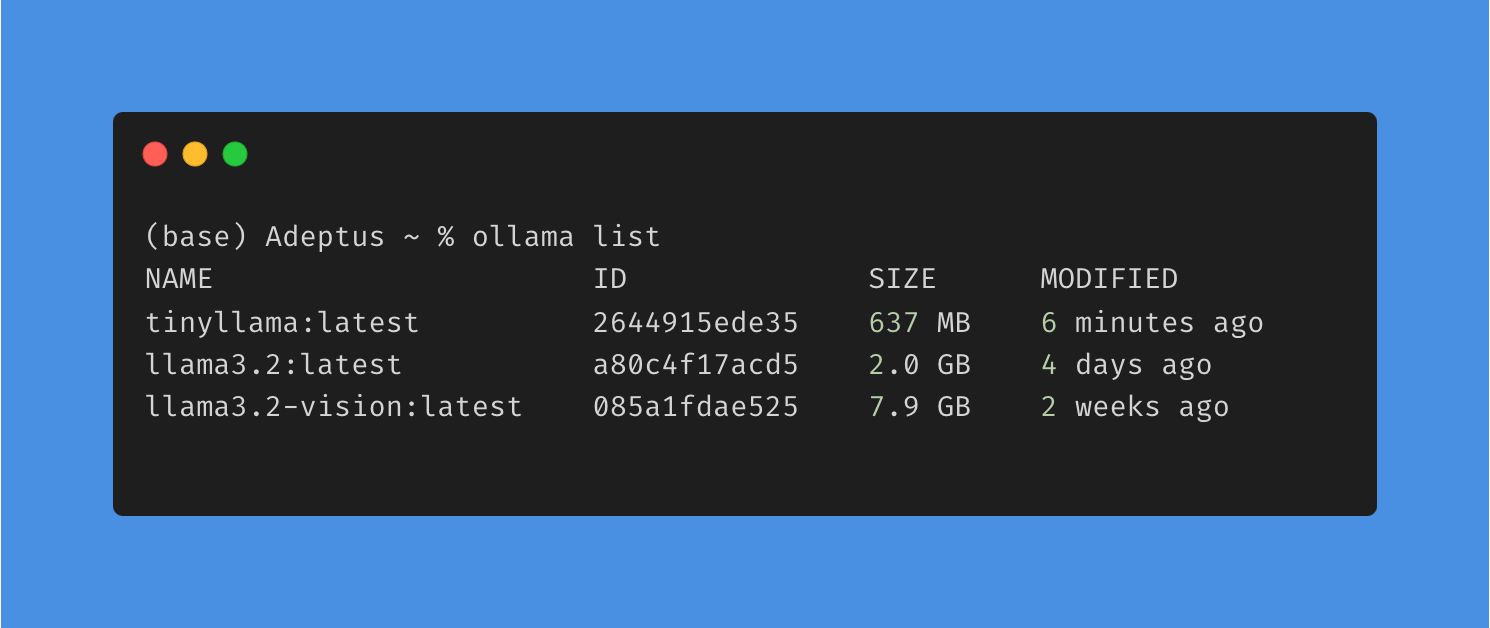
CLI Reference Guide
Basic Commands
- Create a model:
ollama create mymodel -f ./Modelfile- Pull a model:
ollama pull llama3.2- Remove a model:
ollama rm llama3.2- Copy a model:
ollama cp llama3.2 my-modelAdvanced Usage
- Multiline input:
"""Hello,
world!
"""- Multimodal models:
ollama run llava "What's in this image? /Users/jmorgan/Desktop/smile.png"- Process file content:
ollama run llama3.2 "Summarize this file: $(cat README.md)"- Show model information:
ollama show llama3.2
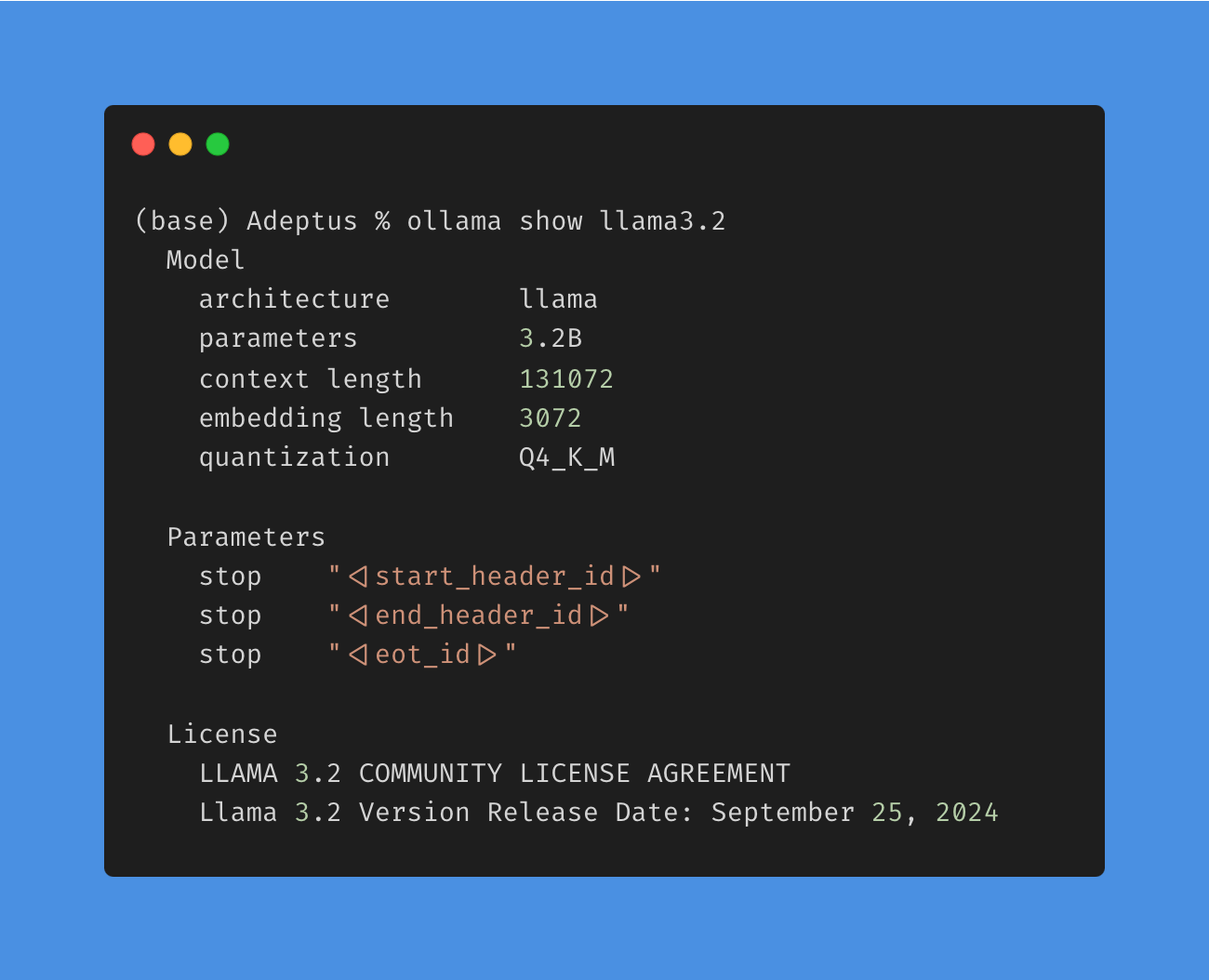
- List running models:
ollama ps- Stop running model:
ollama stop llama3.2Customizing Model Responses
Basic Customization
- Create a Modelfile:
FROM ./vicuna-33b.Q4_0.gguf- Create the model:
ollama create example -f Modelfile- Run the model:
ollama run exampleAdvanced Customization Example
- Pull the base model:
ollama pull llama3.2- Create a custom Modelfile:
FROM llama3.2
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# set the system message
SYSTEM """
You are Mario from Super Mario Bros. Answer as Mario, the assistant, only.
"""- Create and run the custom model:
ollama create mario -f ./Modelfile
ollama run marioLearn More
To learn more about this, do check out